PRÁTICA: VISUALIZAÇÃO NO PYTHON
Prática: Visualização
Agora vamos visualizar a tabela de dados “funcionario” no Python. O padrão utilizado nesta parte do texto é: comando em Python+ saída.
A função que lê arquivos csv é o, pd.read_csv() que pertence a biblioteca pandas do Python.
Como o arquivo que iremos trabalhar está disponível na web , basta informar o link para a função e teremos nossa tabela de dados. Vamos guardar essa leitura numa estrutura do Python tipo data.frame que chamaremos de funcionario.
Este tipo de arquivo pode ser aberto em um editor de texto qualquer, mas como neste tutorial exploraremos o Python, vejamos agora como importar e visualizar um arquivo csv no Python.
O Python possui diversas bibliotecas algumas são nativas e outras não. Alguns exemplos de bibliotecas utilizadas em análise exploratória são Pandas, numpy, matplotlib, matplotlib.pyplot, pylab, seaborn e sklearn.
Primeiramente precisamos importar a biblioteca Pandas, que é uma das principais bibliotecas utilizadas em análise de dados:
funcionario=read_csv("https://docs.google.com/uc?export=download&id=1Pa9jXYztJv42LsUYrJyfUCx8REp0xMfW", sep = ";", encoding = ISO-8859-1)Essa função transforma arquivos csv em objetos data frames (com estrutura de tabela, neste caso é um data frame chamado “funcionario”) e possui alguns argumentos. Se você está lendo um arquivo com texto em português, por exemplo, poderá ser necessáro utilizar o comando enconding para decodificar corretamente os caracteres do alfabeto latino. Os argumentos utilizados foram:
sep: define qual é o separador que está sendo utilizado para separar as colunas;
usecols: utilizado quando queremos importar apenas algumas colunas do arquivo original;
header=None: quando o arquivo não possui cabeçalho. Nesse caso, o comando irá gerar automaticamente valores inteiros como nome para cada coluna.
Agora que a tabela já se encontra no Python, vamos ver algumas funções úteis que nos ajudarão a visualizar nossos dados:
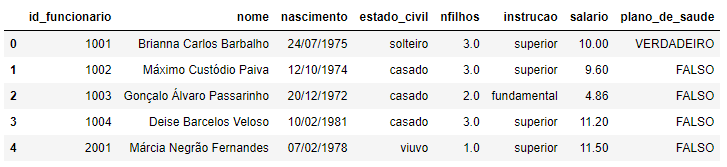
head() retorna as primeiras linhas de todas as colunas da tabela. Para mudar o padrão (default = 8 linhas), pode-se especificar a quantidade de linhas dentro dos parênteses.
funcionario.head(5)
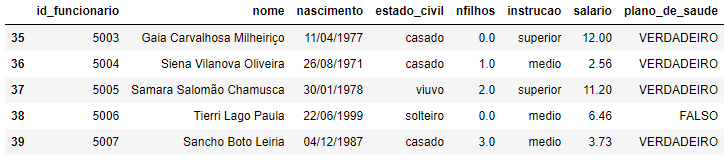
tail() retorna as últimas linhas de todas as colunas da tabela. Para mudar o padrão (default = 8 linhas), pode-se especificar a quantidade de linhas dentro dos parênteses.
Combinando head() e tail() : Nesse exemplo buscamos as 5 últimas observações das 20 primeiras, isto é, as observações 15 a 20 da tabela.

shape retorna o número de linhas e colunas, ou seja a dimensão da tabela.
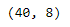
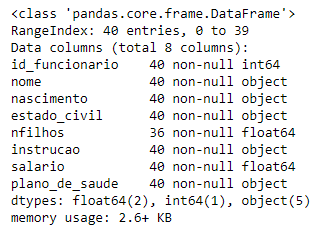
dtypes informa o tipo de dado de cada coluna do objeto funcionario.
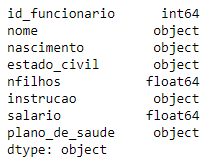
columns informa o nome das variáveis da tabela de dados.

info() traz informações mais detalhadas do que o dtypes incluindo o número de colunas e linhas da tabela, nome das colunas e o formato das variáveis